FaceMatcher3000 POC

Goal
At the WMIL (WarnerMedia Innovation Lab) an interesting project was being considered contemplating a dynamic in-person experience. The idea originated from a “how might we create immersive experience for Lab visitors with our content” type of brainstorm.
As the ideation continued, the WMIL folks and the ContentAI folks talked about different ideas around matching users with celebrities in our content. As we explored various extractors that could be relevant, we collectively settled on a first lightweight proof of concept “can we match a person to a scene or moment in one of our movies or shows?” Thus was born… FaceMatcher3000.
Data
Discovery
To be able to match our face with a face from our content, we need to know what is in our content down to each second of content. ContentAI provides a large number of extractors we can use to extract frame-level insights from our video assets.
ContentAI saves the results from the extractors to a data lake (S3). Most extractors provide json documents as output. The output typically includes the name, confidence and timestamp of when a tag was identified in our content.
For this POC we wanted to evaluate extractors related to finding faces within our content.
Face Match Criteria
In order to get the best results with the least amount of effort, we limited the face match criteria to the following attributes.
- Width
- Height
- Expression (happy, sad, confused, angry, etc.)
- Roll
- Yaw
- Pitch
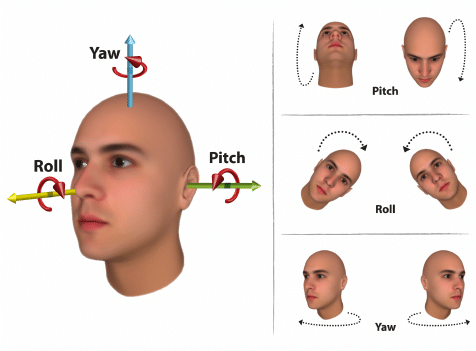
Research ContentAI Extractors
Based on our face match criteria, let's take a look at our existing (and growing) extractor library.
MediaPipe Face Mesh Visualizer
Face mesh seemed very promising at first, but the extractor we have today does not save the data points. We would have to write custom code to save all raw data points. Furthermore, we would have to write custom code to find, to produce the match criteria attributes listed above. As you will find out later, this was going to be overkill for our simple POC goal. I still feel very strongly we can use this data set in a future POC

Azure Video Indexer
Azure Video Indexer provides time segments for when celebrities are detected on the screen. Unfortunately, that is the only information we get back from Azure Video Indexer. Not much we can do with that for our use case.
Openpose
Open pose provides us with a handful of face attributes we can search on.
- Face center (0)
- Right eye (14)
- Left eye (15)
- Right ear (16)
- Left ear (17)
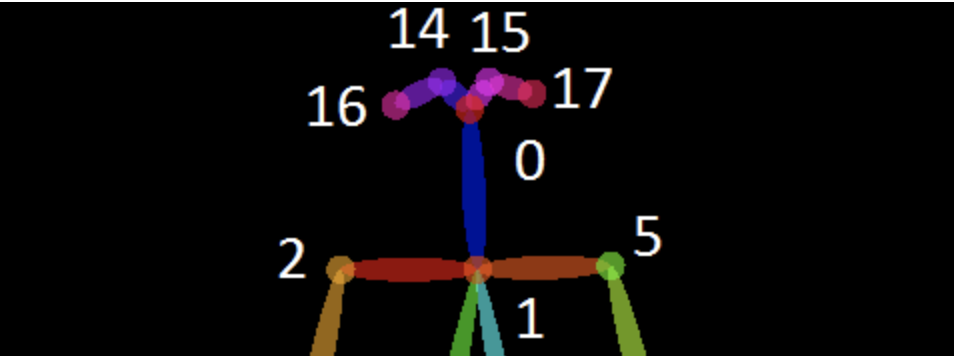
But that's about it, we need more face attributes to make this a fun experience.
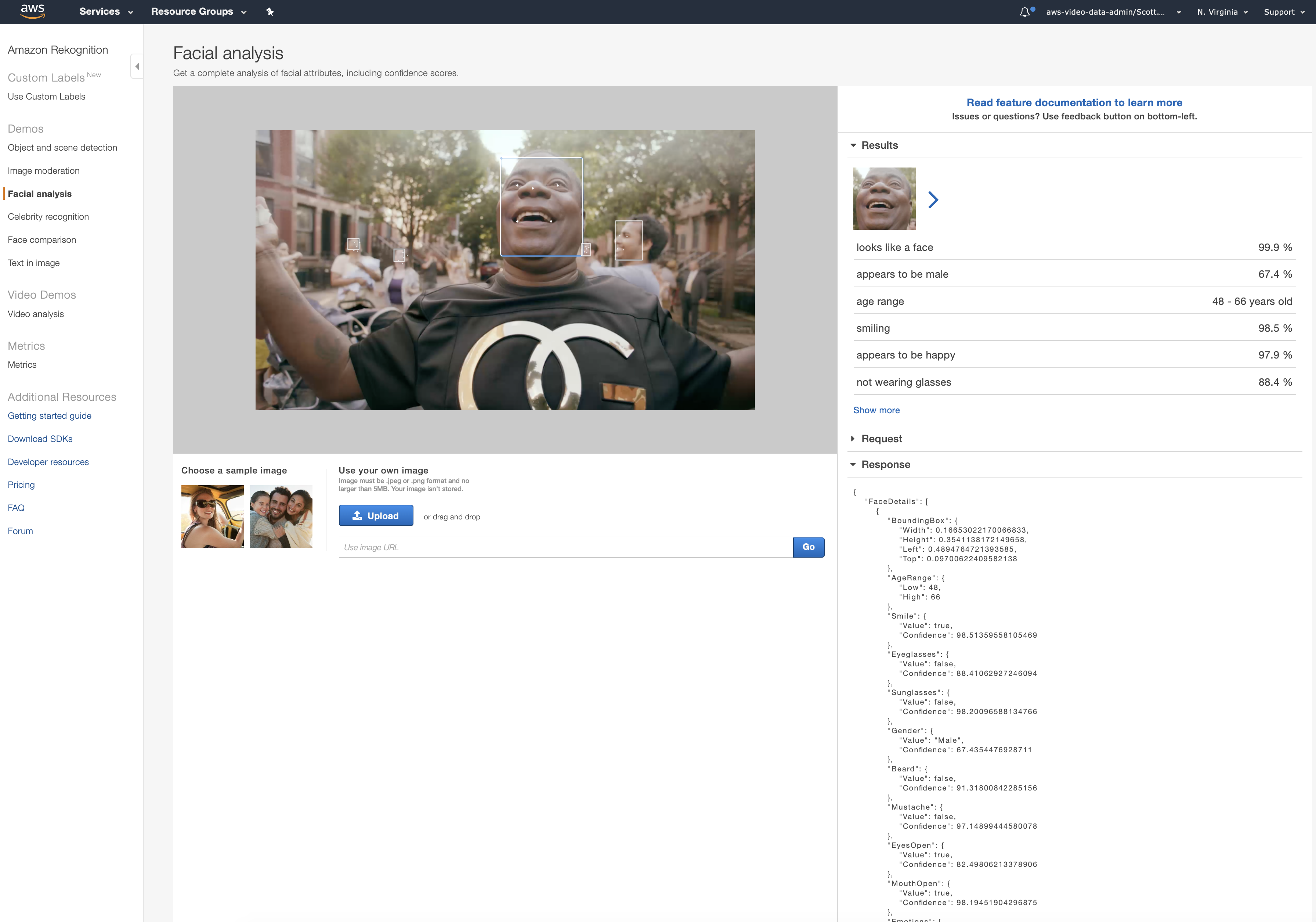
AWS Rekognition Video Faces
AWS Rekognition Video Faces we are able to get the face match criteria values associated with a face without having to write any code.
- Bounding box – The coordinates of the bounding box that surrounds the face. Which we can infer face width and height.
- Pose – Describes the rotation of the face inside the image.
- Emotions - A set of emotions with confidence in the analysis
...and so much more !
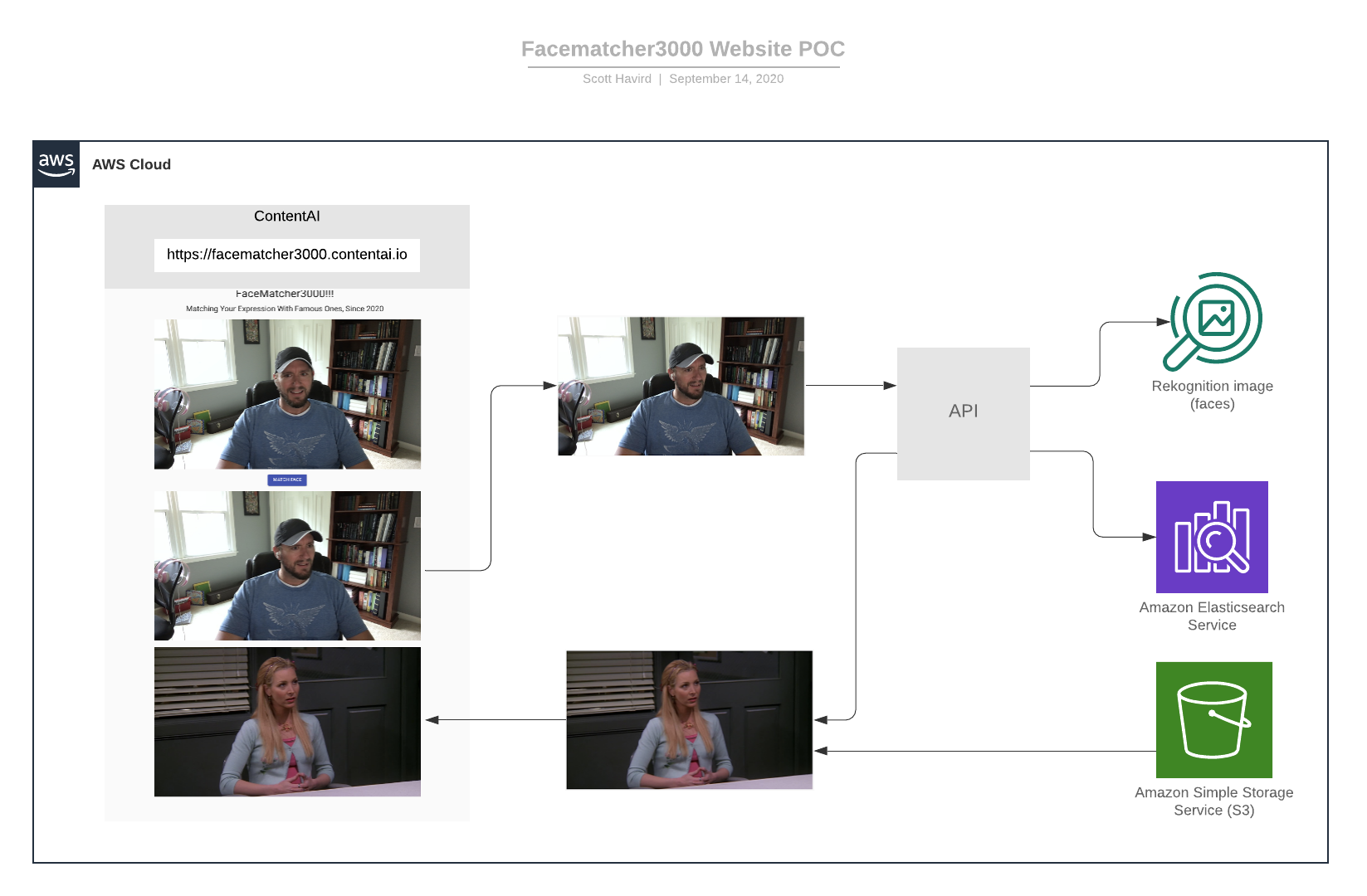
New ContentAI Extractor
Diagram
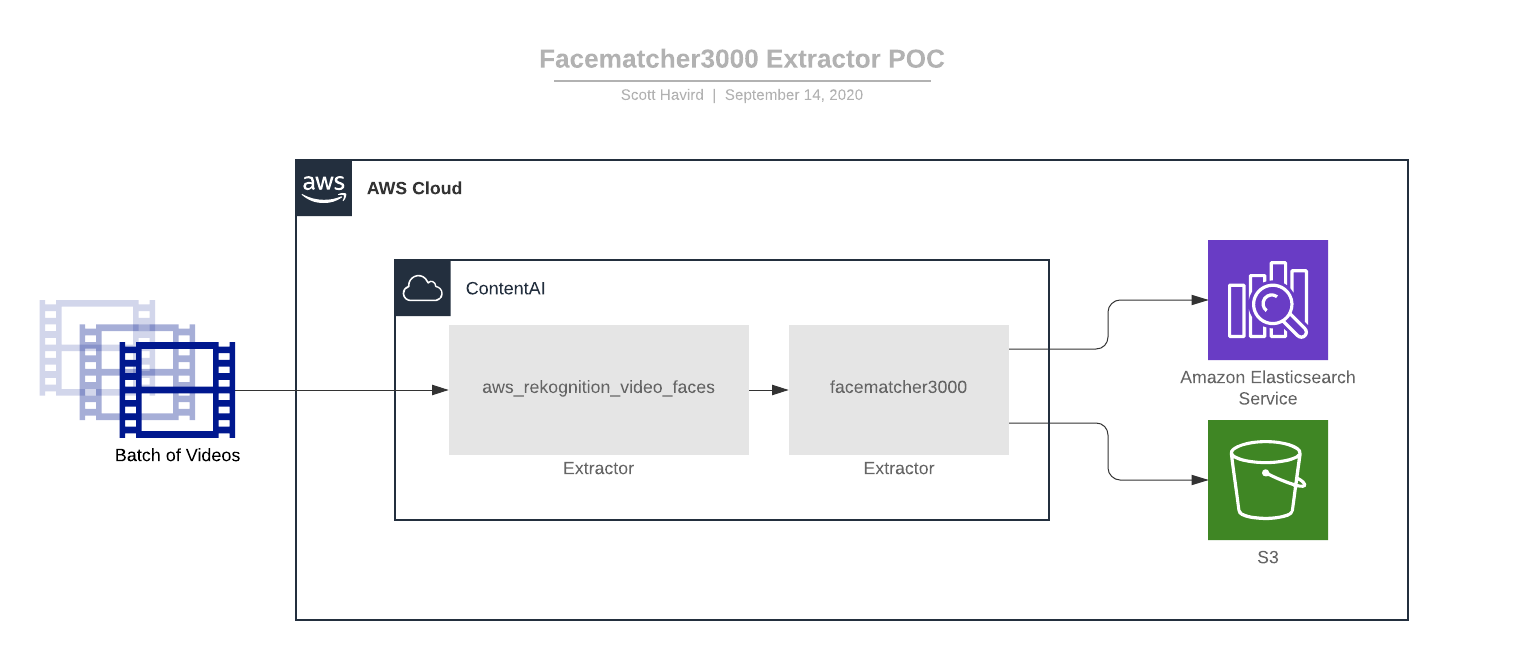
We created a new extractor facematcher3000 which uses the results from aws_rekognition_video_faces, using the platforms extractor-chaining functionality to ..
- insert data into an Elasticsearch index.
- use FFMPEG to capture the image and save it to S3.
Batch processing script
We used the new batch processing feature provided by the ContentAI CLI to run a large number of video assets concurrently. You can learn how to get started with the ContentAI CLI by checking out the docs.
{
"workflow": "digraph { aws_rekognition_video_faces -> facematcher3000; }",
"metadata": {
"name": "facematcher3000",
"description": "elasticsearch and s3 writes"
},
"content": {
"https://content-prod.s3.amazonaws.com/videos/wirewax/FreshPrinceS474.mp4": {
"metadata": {
"franchise": "Fresh Prince",
"season": 4,
"episode": 74
}
},
"https://content-prod.s3.amazonaws.com/videos/wirewax/FreshPrinceS475.mp4": {
"metadata": {
"franchise": "Fresh Prince",
"season": 4,
"episode": 75
}
},
...
...
}
}
Notice we include metadata as a simple way to pass additional information about the video.
Elasticsearch
We decided to use Elasticsearch for storing and searching our data. Elasticsearch meets our needs for geo spatial and range queries.
Index example
{
"id": "314313b-4865-db0a-87a6-c5f6b5851d76",
"_id": "content-prod/videos/wirewax/FreshPrinceS475.mp4/104312-0",
"_index": "facematcher3000",
"_score": 0.6624425,
"_source": {
"key": "content-prod/videos/wirewax/FreshPrinceS475.mp4/00-01-44-312.jpg",
"time": "00:01:44.312",
"confidence": 99.99922180175781,
"franchise": "Fresh Prince",
"season": 4,
"episode": 75,
"height": 0.27242276072502136,
"width": 0.112181156873703,
"emotionType": "CALM",
"emotionConfidence": 79,
"location": {
"type": "point",
"coordinates": [
0.5087340921163559,
0.34011325240135193
]
},
"pitch": 7.025449275970459,
"roll": 3.421329975128174,
"yaw": 1.0114243030548096,
"brightness": 66.44377136230469,
"sharpness": 20.927310943603516,
}
},
As you can see, by using the metadata attribute when starting the job we can now easily access that information when the facematcher3000 downloads the job data and add it to our elastic search database.
S3
We utilize S3 with cloudfront for our web application to consume
API
The API will take in a base64 encoded string of the image you want to match. The image is sent to AWS Rekognition Image Faces API for analysis. We take the results from your face and try to find a match within our Elasticsearch database based off of the match criteria listed above.
We utilized Elasticsearch's Shape query and Range query
Shape query
For finding faces where the center is within the bounding box of your face. When we add more content in the future, we can tighten up the coordinates to get faces closer to the center of your face.
Elasticsearch syntax
Check to see if the point we saved (/PUT) in our Elasticsearch index is within the bounding box (/GET) of the face taken from your camera.
/PUT
{
...
"_source": {
...
"location": {
"type": "point",
"coordinates": [
x,
y
]
}
...
}
}
/GET
{
"geo_shape": {
"location": {
"shape": {
"type": "envelope",
"coordinates": [[minX, maxY], [maxX, minY]]
},
"relation": "within"
}
}
},
Range query
Simple example to illustrate taking the width and height from the response from AWS Rekognition and adding a buffer to width and height so we can get results. If we did not add a buffer it would be highly unlikely that would get an exact match.
When we add more content in the future, we can reduce the buffer size to get a more exact match.
Elasticsearch syntax
/PUT
{
...
"_source": {
...
"height": 0.27242276072502136,
"width": 0.112181156873703,
...
}
}
/GET
{
"range": {
"width": {
"gte": widthLow,
"lte": widthHigh
}
}
},
{
"range": {
"height": {
"gte": heightLow,
"lte": heightHigh
}
}
},
We also use the range query when matching on roll, yaw and pitch
Website
Mock
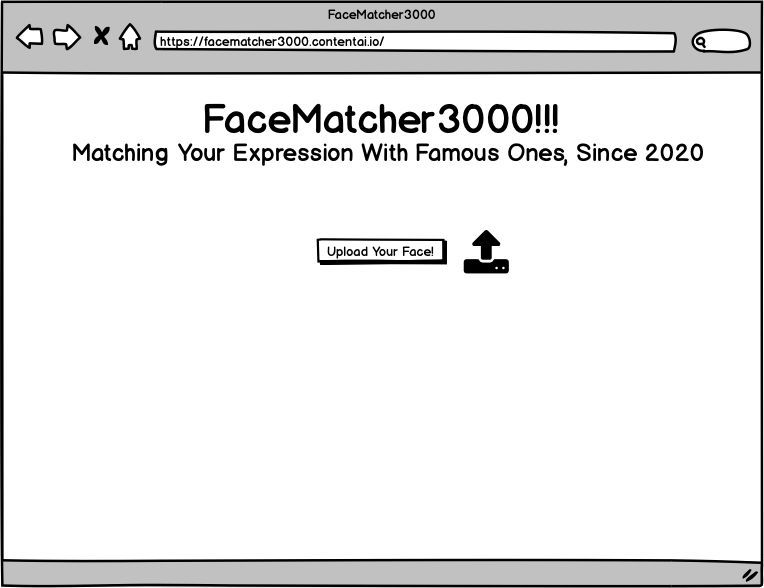
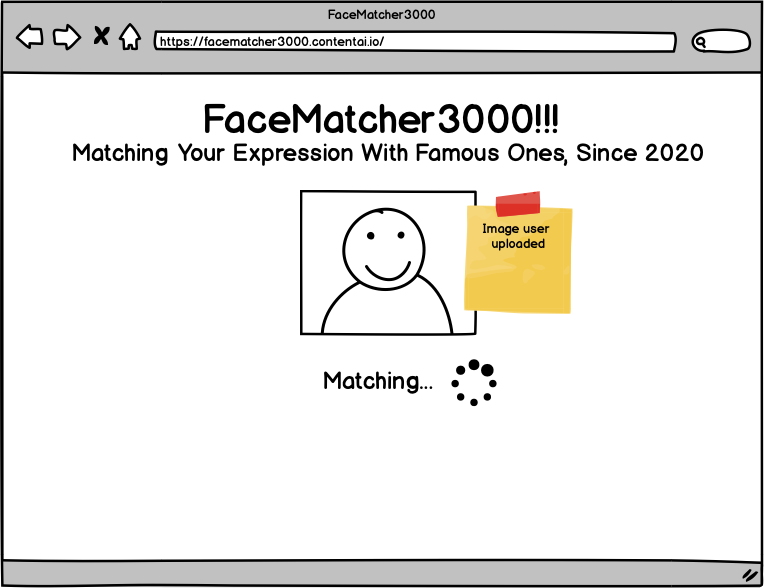
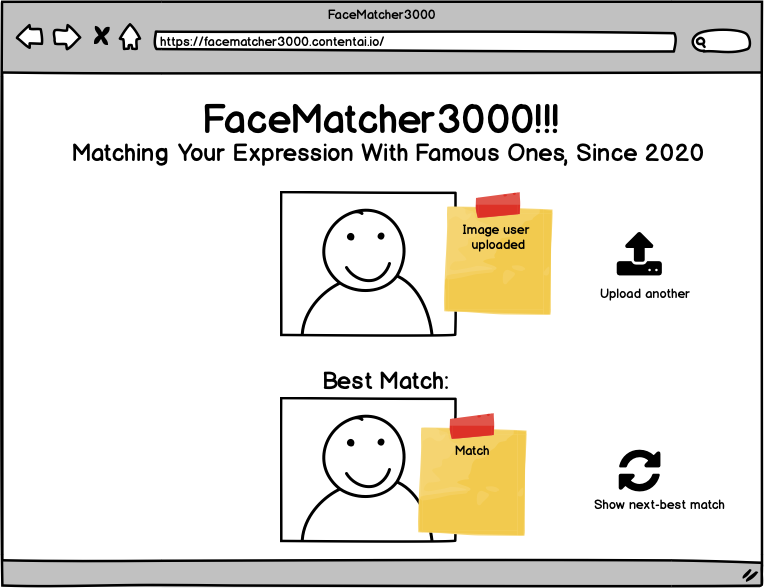
Functionality
- Take a picture using the webcam
- Send image off to our API
- API will call Amazon Rekognition image face detection service
- Use results to query Elasticsearch database
- Return results and image to the web app
- Have the option to save your screenshot and the returned image to your own personal image gallery (local browser storage)
Image Gallery
You can also save some of your favorite results to your own personal image gallery

Cost
We ran extractors on a handful of episodes from Fresh Prince of Bel-Air, Friends and The O.C. Roughly 7 hours of content.
ContentAI
| Extractor | Cost |
|---|---|
| aws_rekognition_video_faces | $42.06 |
| facematcher3000 | $0.14 |
| Total | $42.20 |
One of the many benefits of ContentAI is this is a one time cost. Now that the results are stored in our Data Lake they can be used by any application in the future.
To learn more about calculating the cost for your project please see visit our cost calculator page. Also, if you would like to learn more about getting the data from our Data Lake to use in your application, please check out our CLI, HTTP API and/or GraphQL API docs.
Future Enhancements
-
Adding more videos would further enrich the search-ability of the app.
-
Search on more existing face attributes we already get from aws_rekognition_video_faces
- Age Range
- Beard
- Eye Glasses
- Eyes Open
- Gender
- Mouth Open
- Mustache
- Pose
- Quality
- Smile
- Sunglasses
-
Search on face landmarks. We could automatically create a video like this of your favorite actor.

- We could even add MediPipe Iris detection to the match criteria to give us more data points around the iris then we get from aws_rekognition_video_faces.
- Use MediaPipe Face Mesh to match on approximately 468 data points

Summary
In this POC we used the power of ContentAI to extract face details concurrently using the new batch processing feature. AWS Rekognition Video Faces checked all of our boxes for the face match criteria. Knowing that just extracting the data does not provide very much value, we built a simple application to demonstrate how easy it is to build fun applications using the extracted metadata.
Acknowledgements
The main contributors of this project are Jeremy Toeman from WarnerMedia Innovation Lab and Scott Havird from WarnerMedia Cloud Platforms. I would like to thank John Ritsema for reviewing this blog and providing feedback.